
李沐最新演讲:因“恐惧”而创业我的八个大模型判断
时间: 2024-11-26 11:44:48 | 作者: 米乐m6易游下载
- 方案介绍
正当杨植麟、王小川、张鹏等“清华系”忙碌于搭建中国版GPT时,毕业于上海交大ACM班的李沐辞去了亚马逊的AI研究工作,也扎进大语言模型(LLM)创业中。
创业后,李沐从社会化媒体上消失了整整一年。今年8月,他回到知乎和B站写下了《创业一年,人间三年》,记录他创业第一年的工作。据他说,第一年收入和支出幸运地实现了打平。他又说,接下来更多的公司会在利用LLM降本增效和升级产品上“卷起来”。
正值大语言模型热潮降温,很多人觉得“拿着锤子找钉子”不是一个好迹象——应用没有爆发,再造大模型又有何意义?李沐在这样一个时间段现身,似乎带着一剂强心剂。
李沐的新公司叫Boson AI,他担任CTO(首席技术官),其博士期间的导师Alex Smola担任CEO。Boson是一个物理学概念,指“玻色子”。在量子物理学中,基本粒子被分类为玻色子(Boson)和费米子(Fermion)。也就是说,玻色子和费米子组成了世界。
不过也有人在看了他的自述后,失望地说,一个能给黄仁勋写邮件插队买H100、“偶遇”张一鸣点拨创业思路、在办公的地方得到蔡浩宇拜访、在斯坦福与宿华散步的人,其经验很难被他人借鉴。
8月23日,李沐回到上海交通大学计算机科学与工程系,面对校友发表了一次演讲。在这次演讲中,他谈到对大模型发展的新趋势的判断,也再次剖析了自己的创业心路历程,这一些内容也许仍有借鉴意义。
自从2004年进入上海交大计算机科学与工程系成为第三届ACM班学子以来,李沐一直头顶着“天才”这顶光环。
他的学业履历相当顺利:在交大7年,获得学士、硕士学位,此后短暂在ACM班学长戴文渊介绍下在百度工作,随后投奔卡内基梅隆大学Alex Smola教授,用五年时间获得博士学位。
他的事业旅程令他名利双收。他在百度、Google Brain、亚马逊先后工作,还与陈天奇等人创建了被普遍的使用的深度学习框架MXNet。
为什么选择在2023年创业?他也深知他放弃的是一段更容易的人生道路,而选择创业就是选择经历苦难。李沐讲述了一个关于克服深层次恐惧、用延迟满足说服自己接受苦难、在时间沉淀中去满足深层次欲望的逻辑。
根据李沐的演讲,以下总结了他的八个大模型判断和他的创业心路。为了方便阅读,南方财经全媒体记者对演讲原文进行了整理。
我首先来向不熟悉这样的领域的人来解释一下大模型,大模型的本质就是深度学习,可以把深度学习比喻成“炼丹”。炼丹就是把一堆材料填进一个炉子,依据一个丹方炼出我想要的丹药来。深度学习是把一堆数据喂进一个设备,依据一个算法得出我想要的模型。
设备,或者说算力,得到了产业界投入的大量精力。芯片设计厂商依据摩尔定律,每年把晶体管缩小一半,又增加带宽,把一根光纤传输的数据量翻倍。
但在我看来,数据传输回归到了一些肉眼能够正常的看到的问题上。说白了,我们所做的是把这些芯片尽量压缩在一个最小的空间里。
很多人可能没有看过GPU,GPU其实都放在很高的机架上,层层堆叠。但这样做有个坏处,就是散热不好,空调是不足以给他们降温的,所以现在用上了水冷设备,用高比热容的水来快速散热。
大家可能觉得,光纤用光速传输数据,已经够快的了吧?但在我们看来,一个房间之隔的距离就能带来光纤传输上几个纳秒的延迟,这非常不能忍。所以我们要把光纤缩短,能用一米长绝不用两米。
光有算力其实是不够的,在现代计算系统中,算力越高,所需要的存储空间也越大,所以后者会制约前者的上限。
对于大语言模型而言,它们需要将庞大的数据集压缩并嵌入到模型中,这就要求硬件上具备足够大的内存来存储这一些数据和中间计算结果。然而,内存的物理空间是有限的,如果内存需求过大,可能会在有限的芯片面积上牺牲其他重要组件。
在芯片设计中,内存占用的面积是一个关键考虑因素。随着内存容量的增加,可能会减少芯片上可用的计算单元数量,进而影响整体性能。此外,内存的增加也会带来成本上升和散热问题。因此,芯片设计需要在内存容量、计算能力和成本效益之间做出平衡。
我预计,如果半导体制造工艺没有实质性的突破,例如在晶体管尺寸缩小和三维集成方面的进步,那么单个芯片的存储容量可能会受到限制。具体来说,如果工艺限制导致内存容量难以大幅度的提高,那么模型的大小和复杂度也会在某些特定的程度上受限,这可能会限制在单个芯片上实现超大型模型的能力。这就一定要通过系统架构设计,如多芯片模块或分布式计算系统,来扩展计算和存储能力,以满足大模型的需求。
当算力需求达到一定规模时,供电成本确实成为了一个必须精打细算的关键因素。
我甚至要考虑自行建立发电厂以降低长期成本,因为1000块芯片的耗电量可达一兆瓦,这种规模的能耗可能超过一个校园的总电量需求 。
近年来,算力芯片设计商英伟达获得了垄断地位,导致算力芯片价格成了训练大模型的主要成本之一。短期来看,算力每一次翻倍,价格都会有1.4倍的提升。目前,做推理的芯片可能还有多个品牌选择,但做训练的芯片门槛还比较高,市场选择并不多。
可是在过去很长的一段时间里,在充分竞争的市场里,算力芯片维持了性能翻倍、价格不变的态势。长期看来,我认为市场还是会逐步变得有充分竞争。
我的结论是,在未来,训练大模型的价值会逐年减半。这给我带来的思索是,不要去追逐模型的大小,要更多思考模型能带来什么价值,把这作为你的战略考量。
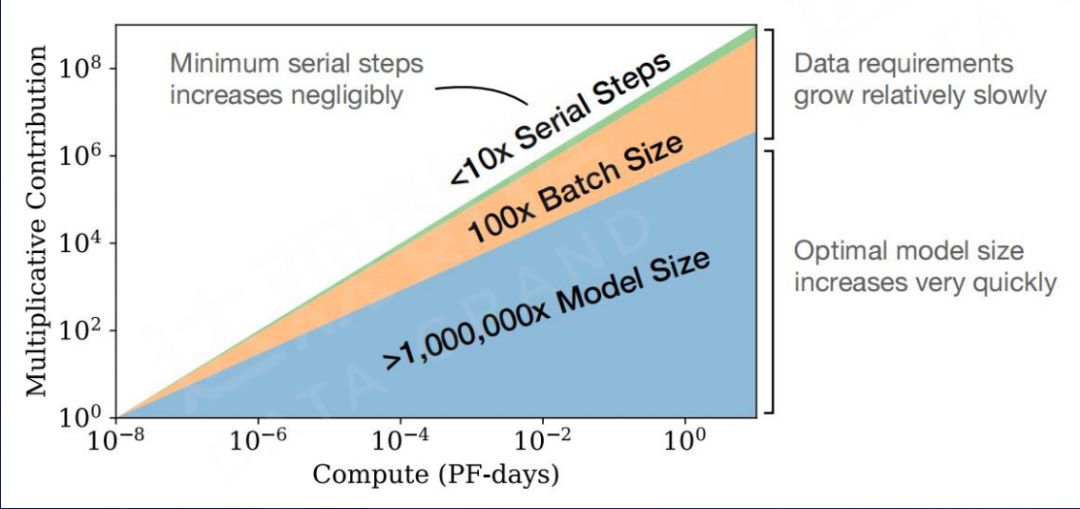
虽然人类历史产生的数据远远不止50T token,但超过这个规模的数据质量并不一定能给大模型带来更好的提升。我认为大模型的可用参数规模会在10万亿到50万亿token之间,也许你能获得更多数据,但通过清洗后会回归到这个数值范围。
就目前的尺寸而言,大模型预训练参数量应该在100B到500B token之间,超过500B不是说训练不动,而是做部署会很难。在Google历史上,它没有真的上线B的模型。在未来一段时间,受限于数据,我认为100B到500B会是大模型的主流尺寸。
在ChatGPT出现之前,我们的人机交互模式是点按钮。不过,点按钮只能满足你80%的需求。
其实点按钮是一个将需求标准化的程序,将一个需求做成了一个按钮(窗口)在那里,但未来,人机交互的目标是实现你更定制化的需求。
如果想实现更精确的需求,长文本、语音会发挥作用。原始的语音信号其实包含很多文本无法覆盖的信息,比如说情绪、方言、性格。语音方面的延迟已经控制在300毫秒以内,能做到交流不被打断的程度,视频方面我觉得发展还没那么快。
很多人都提出要建立垂直模型来解决特定领域的问题,但经过我们长时间的研究,发现这是一个伪命题。
我们的实践发现,如果一个模型要在知识面评测上赢过通用模型,首先要在通用智能的评测上和通用模型几乎打平。
两年前,预训练是技术问题,两年后的今天,它已经是工程问题,而后训练才是技术问题。对于后训练,高质量的数据和改进的算法能够极大地提升模型效果。高质量的数据一定是结构化的,并且与应用场景高度相关,以保证数据的多样性和实用性。
做大语言模型的研究,你可以不去做预训练,你就做后面的一部分,因为后面部分其实对大家有利的。前面变成了一个工程问题,需要很多卡,很多人来完成,后面才是算法创新。
我认为数据决定了模型的上限,而算法决定了模型的下限。如果你想要让模型在某个地方做得好,首先要把这一块的数据准备好,大多数人应该把80%的时间放在数据上。
不过,不管读博士还是打工,都是一个相对简单的关系。公司从最上层把世界的复杂关系抽象成简单任务,一层一层落实下来,越到下面你越是螺丝钉。螺丝钉的工作就是去对应一个螺母钉上去就行了,你不需要去管那个机器有多复杂、外面世界有多复杂。
其实人生动机是由你深层次的恐惧激发出来的。如果你仔细想,你会知道内心有一些特别不愿意分享出来的事情,很多时候我们都选择逃避。我们能满足的是自己浅层的欲望,但这种深层次的恐惧,很少有人能直面。
我的深层次恐惧是什么?很小的时候,我就曾经恐惧人生意义消逝。现在我要直面这种恐惧,我选择把这种恐惧转换成一个向上的动机。
我想选择直面复杂的社会,没有人帮我做抽象,我要去自己把这个社会理解清楚,然后快速学习复杂的环境,自己把一些复杂的事情做抽象。
创业真是最好的经历苦难的办法,我拥有了“婴儿般的睡眠”,每三小时醒一次。
我问了很多人,你们创业的时候是怎么熬过来的,后来总结的核心是延迟满足。工作的话,我今天的工作明天就能得到肯定;读phD的话,需要三年,我才能得到学术成果。创业,我需要更耐心的等待。
这真是一个最好的时代,新的技术带来了新的机会,语言模型对社会的影响将会很大。这也是一个最坏的时代,我知道我需要付出的东西比以往任何一个时间里都要更多。